Introduction to kubernetes
Kubernetes becomes defacto standard runtime environment for modern cloud-native applications. As a developer, you should understand the basic concepts behind and operate the application reasonably in DevOps mode. This post aims to explain basic concepts and provide a solid grounding you can further improve your knowledge and prepare you for day-to-day work and potential interview questions. This post is organized as a series of closed topics where understanding those areas should allow you to answer a range of questions. Kubernetes is a complex system, so we simplify things. If you want to prepare for Kubernetes Certified Developer (KCD), this post can be a stepping stone.
What is Kubernetes
Kubernetes is an open-source container orchestration tool for managing multi-container (e.g. by docker) applications. It is in some sense similar to docker swarm or loosely related to docker-compose. Kubernetes was initially developed by Google and released as open-source in 2014.
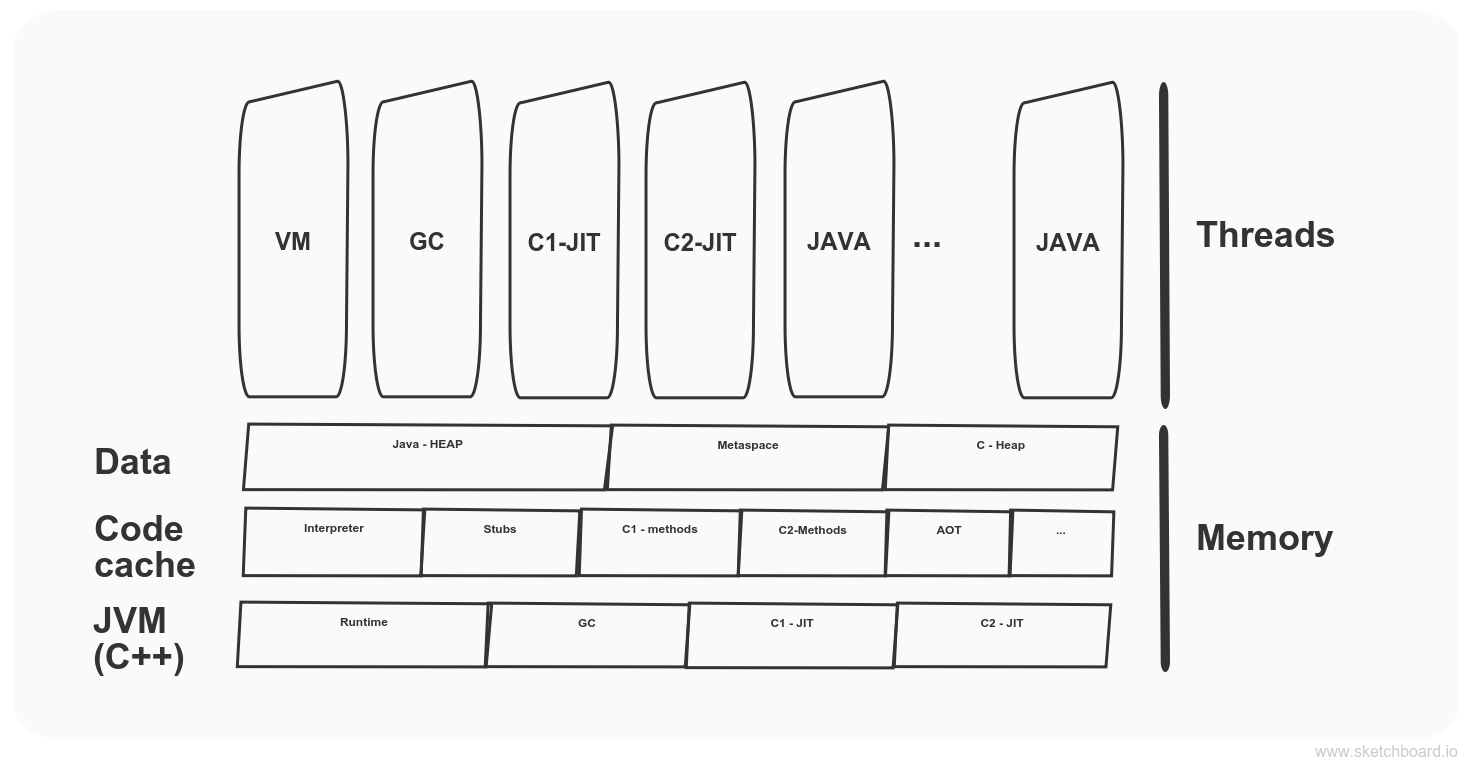
Simplified kubernetes architecture diagram
After reading this section, you should be able to answer the following questions:
- What are the components of the kubernetes cluster?
- What are the row responsibilities of those components?
We are not going into great detail to provide a high-level context as this post is not aimed at Kubernetes administrators but rather developers.

Master node
The master node is responsible for the management of the cluster and is running control plane components. Kube-apiserver expose APIs for management. Controller managers consist of two distinct types: cloud and Kube related. Cloud controller embed a cloud-specific control logic while Kube related take care of kubernetes cluster related things, e.g. node statuses, the job runs, access token creations etc. All data are stored in etcd key-value store. Kube-scheduler is responsible for newly created pods and select nodes to run them. It takes into consideration various limitations and specifications for a given pod.
Worker Nodes
Worker nodes are running workloads and consist of Kublet and kube-proxy. Kube-proxy is a network proxy running on each node in the cluster and is responsible for network communication according to configuration. Kublet runs on each node as well, and his responsibility is to make sure that pod containers are running and healthy.
Kubernetes basic concepts
After reading this section, you should be able to answer the following questions:
- What is kubernetes manifest?
- What is a kubernetes pod?
- What is a control manager?
- How kubernetes control loop operate?
Kubernetes control loop – the heart of the kubernetes
Kubernetes is based on the modern declarative DevOps principle that you describe the desired state of things rather than a set of steps that lead to that state. At the heart of Kubernetes, there is a control loop that constantly evaluates a current state versus a desired state and requests appropriate corrections that should lead towards it. The desired state in the Kubernetes is described as a Kubernetes manifests, a bunch of YAML files, that describes a state for various kubernetes objects called kinds, e.g. deployment. Controllers continuously execute the control loop and drive changes, usually through an apiserver. The controller is typically responsible for one or more kubernetes types/kinds. The basic kind which acts as a unit of scalability in kubernetes is called a pod. The pod can consist of one or more containers with specified parameters.
Kubernetes object kinds
After reading this section, you should be able to answer the following questions:
- What is the difference between service and ingress?
- How are kubernetes objects organized?
- What is a daemonset good for?
- What is the difference between deployment and stateful set?
- How to store sensitive information in the cluster?
- What are lower-level kubernetes objects?
Basic Kubernetes object kinds
Kubernetes deployment consists of various abstractions over infrastructure that are described in kubernetes as object kinds. They can be divided according to different criteria:
- High-level kinds vs lower level kinds
- Stateful vs stateless
- Ephemeral vs permanent kinds

The image above describes the basic kinds used in kubernetes deployment. As mentioned earlier, the basic unit of scalability and deployment is a pod. Pod represents a set of containers with associated resources granted to them. Because a pod is a transient object that can be freely moved in the cluster, e.g. by re-scheduling, kubernetes provide a service object used as a permanent locator/address within a cluster (implements a service locator pattern). Service can be represented by, for example, a load balancer. The sole purpose of ingress is to reach the pods running in the cluster from the outside world. Ingress is typically represented by cloud global HTTPS load balancer and/or Nginx proxy server or similar. Trafic is further routed based on the host header to the appropriate service within the cluster. As the pod is transient, so the container does. To provide persistent storage to a container, the concept of persistent volume claim (pvc) addresses this requirement. ConfigMap object provides a set of “static” files, e.g. for container configuration purposes. In comparison, secrets offer a way how to access sensitive information from containers.
Those lower-level objects can be further abstracted by kubernetes higher-level kinds like deployment or stateful sets, which removes a need to specify replica sets. Deployment is primarily aimed for stateless applications, while stateful set provides ways to maintain pod identity through pod restarts or relocation, e.g. moving storage around or keeping communication to a given pod.
Different runtime requirements
To address the different needs for applications runtime, kubernetes introduces a few more concepts: Kubernetes jobs and deamon sets. A deamon set is a special kind of deployment pod that runs on every VM machine from a node pool. This kind of deployment is typically used for VM metrics collection etc. Kubernetes jobs provide a way how to run a single task in the kubernetes cluster. For example, spinnaker custom stages are managed this way.
Object versioning
Nearly every object in kubernetes has its version. So it is possible to restore any version running by activating those. Unfortunately, the only exceptions to those rules from the basic objects mentioned above are ConfigMaps and Secrets (if I am not mistaken). Restoring a deployment version without a corresponding version of configuration is one of the big shortcomings, and in my opinion, the decision was unlucky. There are techniques how to deal with that.
Interaction with kubernetes cluster, managing kubernetes deployment
After reading this section, you should be able to answer the following questions:
- What is a key tool for interaction with the cluster?
- What are the basic operational models/deployments?
- How do you manage resources?
- What is the difference between liveness and readiness probe?
Kube control
When interacting with the Kubernetes cluster directly, the key tool is Kube control (kubectl). Kubectl is a command-line utility that interacts with a cluster api server. It allows you to add or remove deployment, get the version of any manifest file. It also provides a set of administrative commands.
Using kubectl, you can drive a deployment as a rolling upgrade ( as a default scenario), a more advanced procedure via replica controllers or just simple scaling up or down pods (as shown in the example).
kubectl scale --replicas=3 deployment/mysql
Resource management
Every pod specification contains a section of manifest dedicated to resources. The resource requests section specifies resources necessary for starting the pod containers, which the scheduler uses to plan a deployment. The resource limit section defines resources that cannot be exceeded, and the pod will get killed or throttled. This is a fundamental mechanism for configuring resources from bursty to guaranteed load and one way that affects the quality of service.
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
Kubernetes probes
Every pod is evaluated in the kubernetes control loop to correct potential differences from the desired state. To make sure that the pod is ok kubernetes use liveness and readiness probes mechanism. The liveness probe checks whether your application is up and running. If not, kubernetes will kill and restart the pod. The readiness probe checks whether the pod can accept and process new requests. As a software developer, you should provide such endpoints that correctly implement the logic to provide such insight. Only with correctly implemented endpoints, you can achieve a zero-downtime deployment.
Kubernetes advanced topics
After reading this section, you should be able to answer the following questions:
- How do you govern application uptime? ~ pod disruption budget
- How do you adopt an application to various load scenarios? ~ autoscaling
- How do you isolate applications from each other?
- How to achieve an advanced deployment strategy?
Advanced kubernetes kinds
A lower-level concept called Replica Set is responsible for scaling out a pod to handle more traffic. This concept is a key for basic and more advanced deployment strategies like rolling upgrade (basic) or blue-green deployment. By extension of this capability is to provide automatic scalability using a horizontal pod autoscaler, where the server changes the number of replicas for a given pod. Contrary to guaranteeing some application availability running in a pod, you can define a pod disruption budget that describes the rules of how pods can be changed.
Kubernetes deployment isolations
Every deployed object to kubernetes is deployed to a namespace which acts as a logical separation of deployments in a single cluster. If a namespace is not specified, then the default namespace is used. System namespaces are also created, e.g. kube-system or kube-public. Those are used for deployments supporting kubernetes cluster operations.
To isolate deployments on the network level, you need to specify a network policy. Network policy allows you to restrict how a pod is allowed to communicate with various network entities.
Conclusion
In this post, we briefly touched all core concepts in Kubernetes that developers should be aware of to build a secure, stable and resilient solution. The information loads this post, and we often oversimplified the concept to make it digestible for newcomers. Please, let me know if I missed some vital concept or oversimplified something that deserves a more detailed explanation or is not clear enough. You can leave a comment here or reach me on Twitter













 The difference in runtime characteristics is also significant as the benchmark results show. With disabled inlining:
The difference in runtime characteristics is also significant as the benchmark results show. With disabled inlining: