Working on the next project using again awesome Apache Kafka and again fighting against a fundamental misunderstanding of the philosophy of this technology which probably usually comes from previous experience using traditional messaging systems. This blog post aims to make the mindset switch as easy as possible and to understand where this technology fits in. What pitfalls to be aware off and how to avoid them. On the other hand, this article doesn’t try to cover all or goes into much detail.
How Kafka compares to traditional messaging systems
Apache Kafka is system optimized for writes – essentially to keep up with whatever speed or amount producer sends. This technology can be configured to meet any required parameters. That is one of the motivations behind naming this technology after famous writer Franz Kafka. If you want to understand the philosophy of this technology you have to take a look with a fresh eye. Forget what you know from JMS, RabbitMQ, ZeroMQ, AMQP and others. Even though the usage patterns are similar internal workings are completely different – the opposite. Following table provides a quick comparison
|
JMS, RabbitMQ, …
|
Apache Kafka
|
|
Push model
|
Pull model
|
|
Persistent message with TTL
|
Retention Policy
|
|
Guaranteed delivery
|
Guaranteed “Consumability”
|
|
Hard to scale
|
Scalable
|
|
Fault tolerance – Active – passive
|
Fault tolerance – ISR (In Sync Replicas)
|
Kafka queue
Core ideas in Apache Kafka come from RDBMS. I wouldn’t describe Kafka as a messaging system but rather as a distributed database commit log which in order to scale can be partitioned. Once the information is written to the commit log everybody interested can read it at its own pace and responsibility. It is consumers responsibility to read it not the responsibility of the system to deliver the information to the consumer. This is the fundamental twist. Information stays in the commit log for a limited time given by retention policy applied. During this period it can be consumed even multiple times by consumers. As the system has reduced set of responsibilities it is much easier to scale. It is also really fast – as sequence read from the disk is similar to random access memory read thanks to effective file system caching.
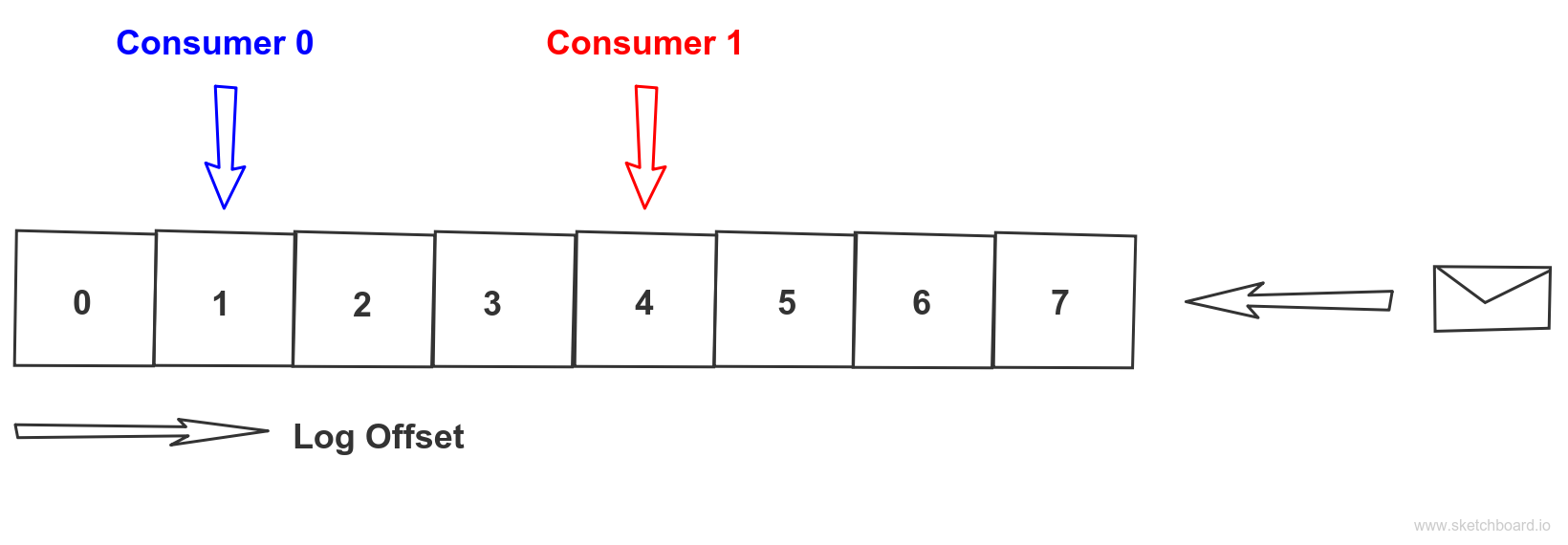
Kafka scalability
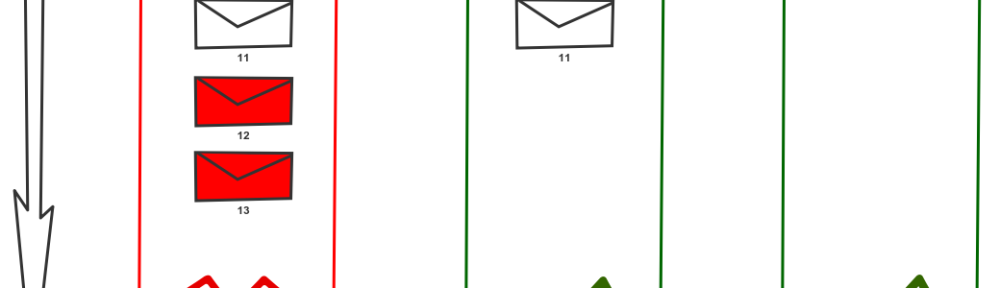
Topic partition is a basic unit of scalability when scaling out Kafka. Message in Kafka is simple key-value pair represented as byte arrays. When message producer is sending a message to Kafka topic a client partitioner decides to which topic partition message is persisted based on message key. It is a best practice that messages that belong to the same logical group are sent to the same partition. As that guarantee clear ordering. On the client side, exact position of the client is maintained on per topic partition bases for the assigned consumer group. So point to point communication is achieved by using exactly the same consumer group id when clients are reading from the topic partition. While publish-subscribe is achieved by using distinct consumer group id for each client to topic partition. The offset is maintained for consumer group id and topic partition and can be reset if needed.
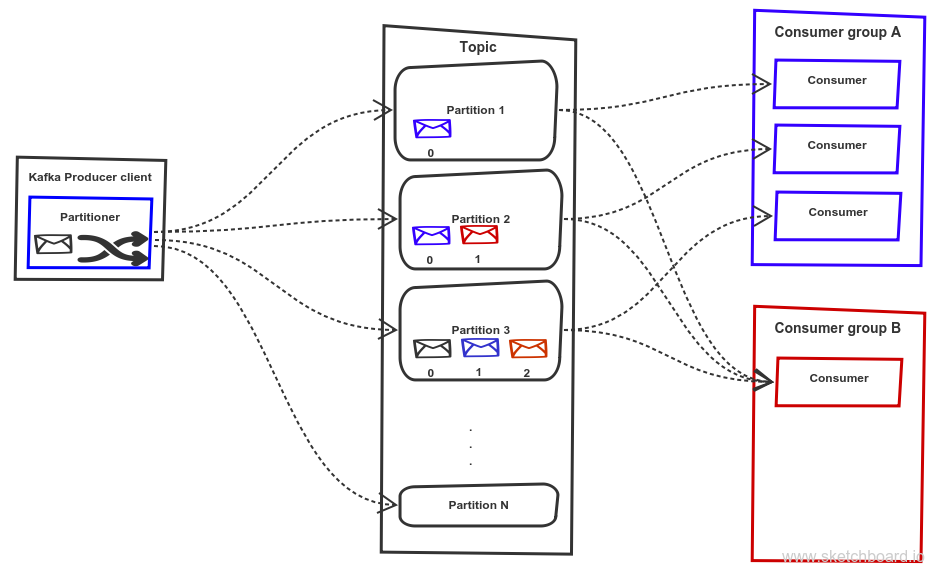
Topic partitions can be replicated zero or n times and distributed across the Kafka cluster. Each topic partition has one leader and zero or n followers depends on replication factor. The leader maintains so-called In Sync Replicas (ISR) defined by delay behind the partition leader is lower than replica.lag.max.ms. Apache Zookeeper is used for keeping metadata and offsets.
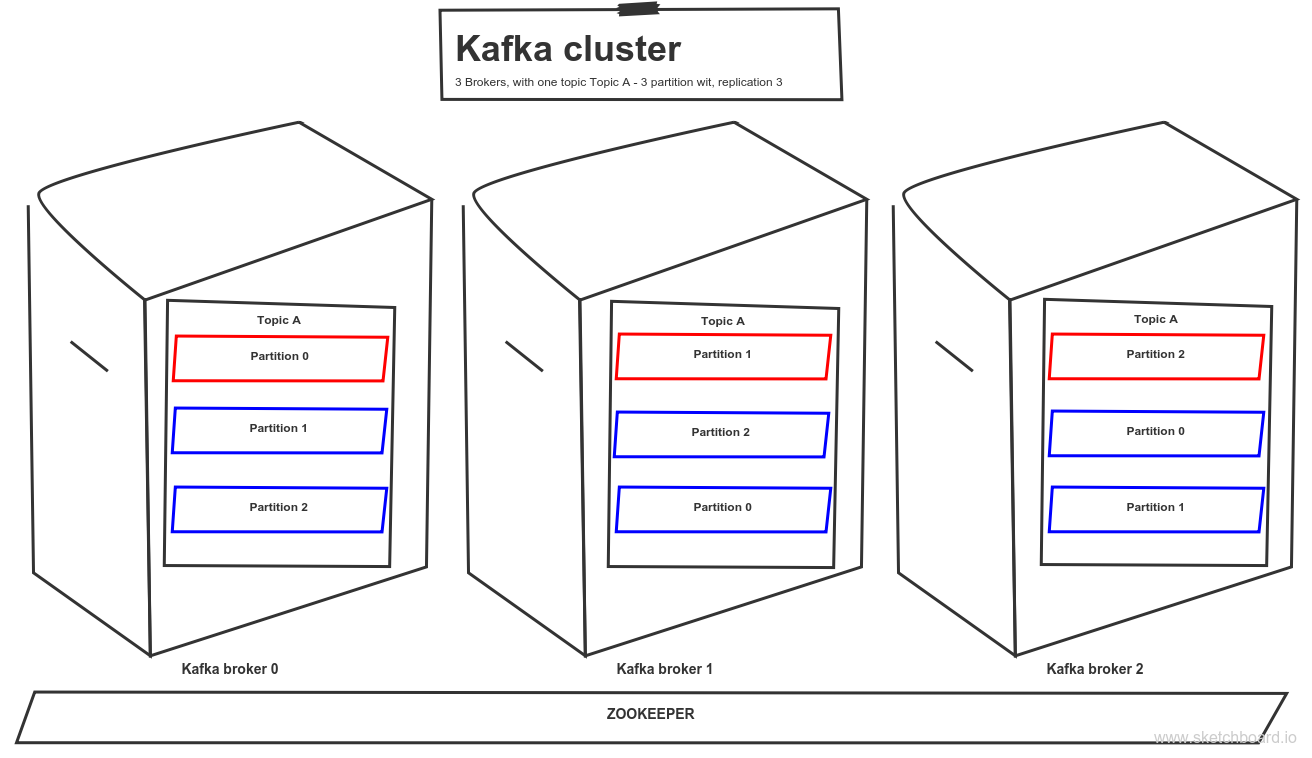
- acknowledge – broker acknowledge to producer message write
- commit – the message is written to all ISR and consumer can read
- 0 – producer doesn’t wait for confirmation
- 1 – wait for acknowledge from the leader
- ALL – wait for acknowledge from all ISR ~ message commit
Apache Kafka configuration options
Apache Kafka is quite flexible in configuration and as such, it can meet many different requirements in terms of throughput, consistency and scalability. Replication of topic partition brings read scalability on the consumer side but also poses some risk as it is some additional level of complexity to achieve this. If you are unaware of those corner cases it might lead to nasty surprises, especially for newcomers. So let’s take a closer look at following scenario.
Loosing messages scenario
We have topic partition with a replication factor 2. Producer requires highest consistency level, set to ack = all. Replica 1 is currently the leader. Message 10 is committed hence available to clients. Message 11 is not acknowledged nor committed due to the failure of replica 3. Replica 3 will be eliminated from ISR or put offline. That causes that message 11 becomes acknowledged and committed.
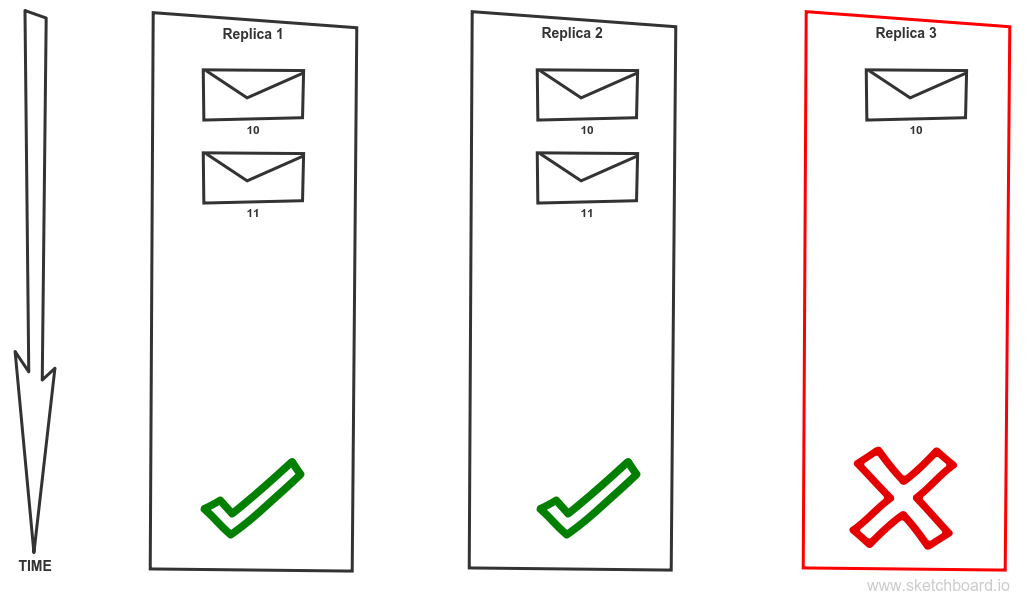
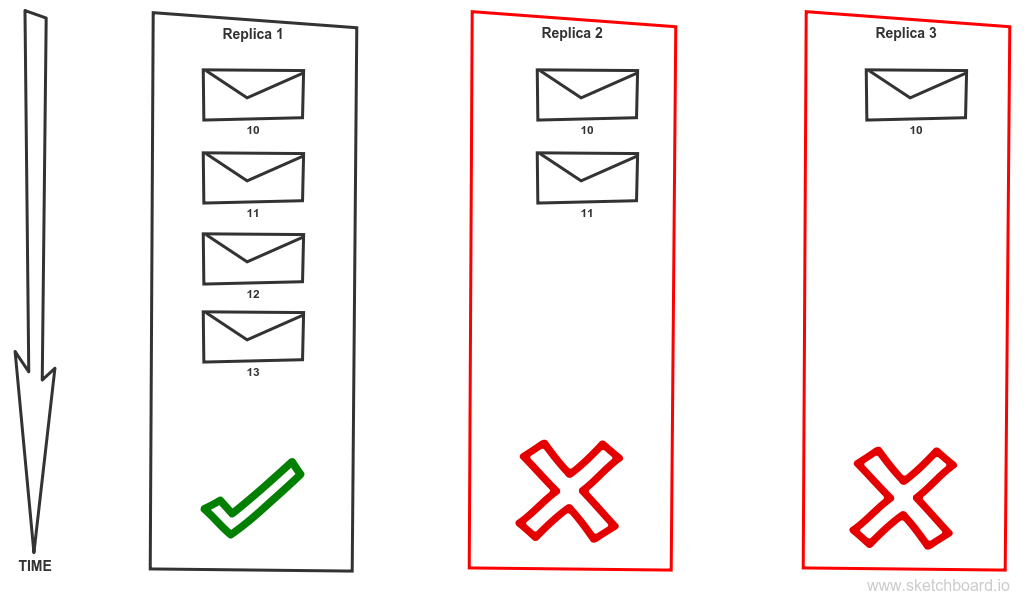
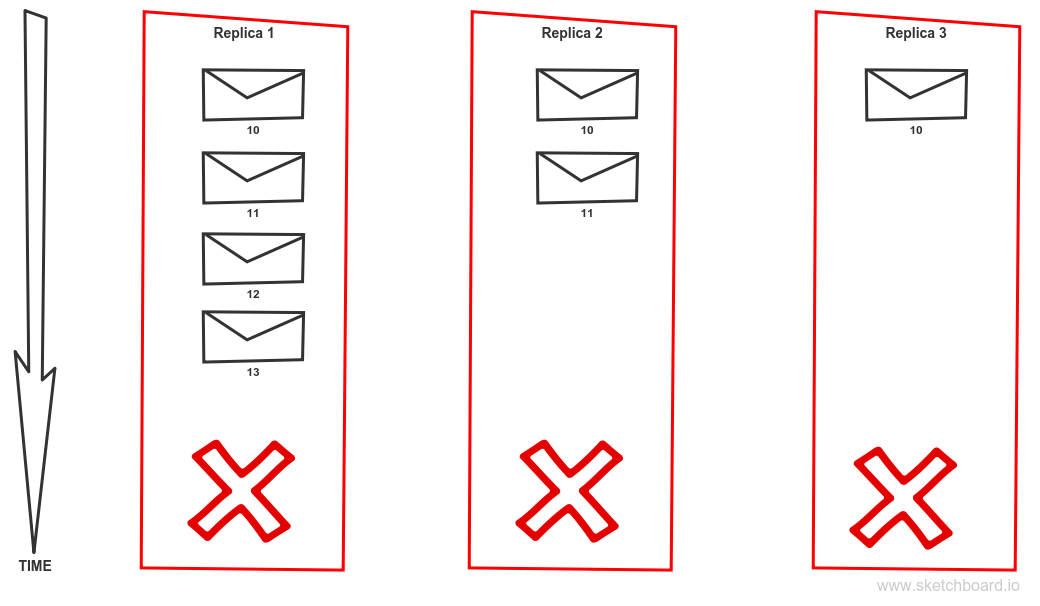
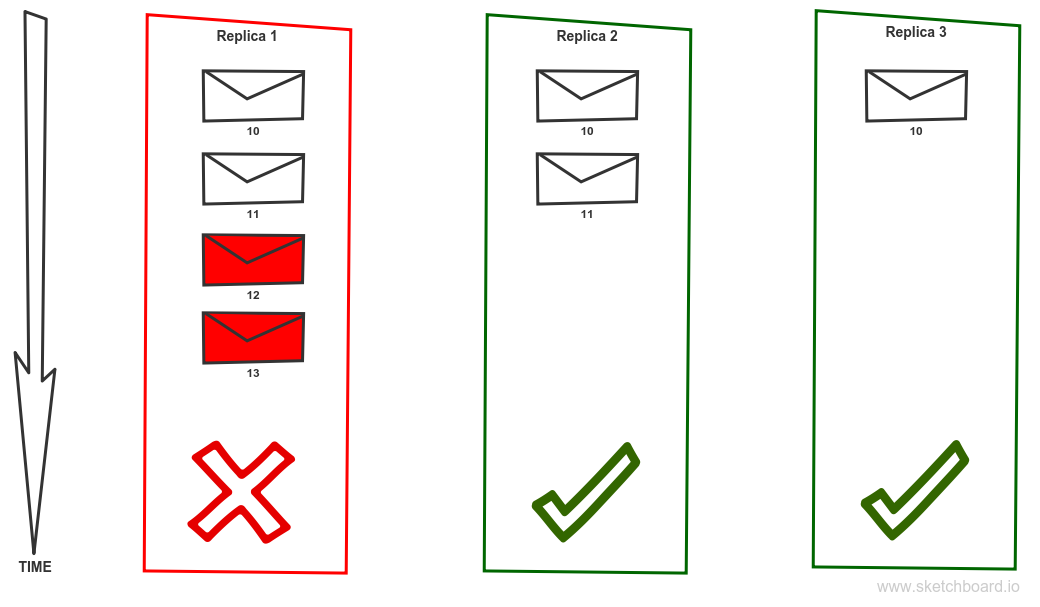
Is that a problem? Well, the correct answer is: It depends. There are scenarios where this behaviour is perfectly fine. Imagine collecting logs from all machines via sending them through Kafka. On the other hand, if we implement event sourcing and we just lost some events that we cannot recreate the application state correctly. Yes, we have a problem! Unfortunately, if that doesn’t change in latest releases, that is default configuration if you just install new fresh Kafka cluster. It is a set up which favour availability and throughput over other factors. But Kafka allows you to set it up in a way that it meets your requirements for consistency as well but will sacrifice some availability in order to achieve that (CAP theorem). To avoid the described scenario you should use the following configuration. The producer should require acknowledging level ALL. Do not allow kafka perform a new leader election for dirty replicas – use settings unclean.leader.election.enable = false. Use replication factor (default.replication.factor = 3) and require minimal number of replicas to be in sync state to higher than 1 (min.insync.replicas = 2).
Message delivery quarantees
We already quickly touched the topic of message delivery to the consumer. Kafka doesn’t guarantee that message was delivered to all consumers. It is the responsibility of the consumers to read messages. So there is no semantics of persistent message as known from traditional messaging brokers. All messages sent to Kafka are persistent meaning available for consumption by clients according to the retention policy. Retention policy essentially specifies how long the message will be available in Kafka. Currently, there are two basic concepts – limited by space used for keeping messages or time for which the message should be at least available. The one which gets violated first wins.
Data cleanup
When I need to clean the data from the Kafka (triggered by retention policy) there are two options. The simplest one just deletes the message. Or I can compact messages. Compaction is a process where for each message key is just one message, usually the latest one. That is actually the second semantics of key used in the message.
Kafka “missing” features
What features you cannot find in Apache Kafka compared to traditional messaging technologies? Probably the most significant is an absence of any selector in combination with listening (wake me on receive). For sure can be implemented via correlation id, but efficiency is on the completely different level. You have to read all messages, deserialize those and filter. Compared to a traditional selector which uses the custom field in message header where you don’t need even to deserialize message payload that is on the completely different level. Monitoring Kafka on production environment essentially concerns elementary question: Are the consumers fast enough? Hence monitoring consumers offsets with respect to the retention policy.
Kafka was created on LinkedIn to solve a specific problem of modern data-driven application to fill the gap in traditional ETL processes usually working with flat files and DB dumps. It is essentially enterprise service bus for data where software components need exchange data heavily. It unifies and decouples data exchange among components. Typical uses are in “BigData” pipeline together with Hadoop and Spark in lambda or kappa architecture. It lays down foundations of modern data stream processing.
Conclusion
This post just scratches basic concepts in Apache Kafka. If you are interested in details I really suggest to read following sources which I found quite useful on my way when learning Kafka:
- This article describes core ideas behind Kafka
- Official documentation is pretty good as well
- If you are concerned about performance you can find your answers in this white paper
- Also, need to mention a great book from original creators here

Great post, thank you!
LikeLike
Just a small correction to the diagram in the blog …the consumers in consumer group A and the consumers in the consumer Group B should also consume messages from partition N…as well..
https://polldaddy.com/js/rating/rating.js
LikeLike